����������ĸ������뷽�� ��ҫ�� ��ʤ�� �� ��ժ Ҫ���������м��������������뷽���IJ�������������Ϊ���߱��������Զ���������������ĸ�����������������ֱ�ȱ����һ���ö��Զ���������������ĸ���Խ���Ӧ�ñ����ķ�ʽ��������һ���ⳤ���������ܵõ���Ч�������������ֻ�ܴ����õĽǶ�ȥѰ���Ľ������������Ҫ����ĺ���Ҫ���ö��Զ��������Խ��б�����ͬ��������Բ������·������Ĵ����������û�����ʶ��������Ѱ�Ҳ���ʾ���ֶ��Զ���������������ĸ����˽������Ӧ���ѵ�Ĺؼ���
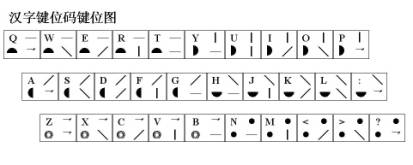
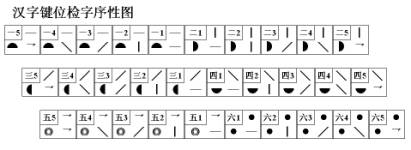
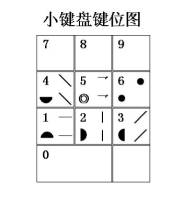
���Ĵ�Ϊ����Ѱ��������ĸ�Ĺؼ����֣���������ĸ���ڵĻ��Ƽ���ϵͳӦ�÷����ͱ��뷽�������������� ����һ���ж����ܣ����ع��ܺ����ع��ܣ����ڸ��Եı�������ͬ����������Ӧ��������ĸ��������ĸ��Ϊ������ԡ���ĸ���ֺ����ѽ��������ѵ����غ�������ĸȷ�������ˣ���Ӧ�������ܷ��㡣 ���ֵ���������ͨ��������ĸ���ֵ���ĸ����ʵ�֣�������ȴ���ں��ֹ��츴�ӣ�����Ҫ�����Σ�����ֱ������ĸ�ķ�ʽ���б��������м��������������뷽���IJ��ϳ��֣�һֱ����Ϊ�Dz��ܽ������ں��ֵ�������ĸ�ģ��ʷ���һ��ֻ��Χ��ʵ��Ӧ������ij��ֶ�չ�����ھ�������ʷ�������ش�ı����Ժ���ȡ��Ӧ�������ϵͳ�Խ��������ʹӦ�ô����ͺ�״̬�� ��ô�������Ƿ�Ҳ�߱���������������ĸ�������ͽ���ϵͳӦ���أ������Ǿ����������һ��̽��: 1���Ժ���������ĸ����ʶ ͨ�����������ֵıȽϿɷ��֣���ĸ���ֵ�������ĸ��һ�鰴����������ɵķ��ţ�ÿ����ĸ���Ǹ��������е�һ�����Ե㣬����ĸ���ֿ�������ĸ�IJ�ͬ����˳����ж�������������������ͬ��������ǰѱʻ�������Ļ������ɵ���ɵIJ�����һ���飬�ɿ���ɵĺ��־���һ�����ˡ�����㡢�顢���У��������ڵ����Ԫ̫��(һ��Ϊ5��)�������������������һ����λ��ܳ������������ֻ�ܶ࣬���������루һ����λȡ4λ���ң�����Dz����ˡ����ÿ���������������̶���̬�����߱�������������Ҳ�Ͳ��ܽ������������Կ��Dz���ֱ�Ӷ����������ġ���������ǶԵ���������Ҫ�ؽ����ʵ����䣬ʹ��������������ܹ�����������һ����յ���������������ô������Ҳ�;߱��˽���������ĸ�Ļ��������� ����֪������Ϊ�ʻ��ĵ��ǿ��������ģ����ǿ��Ѱ�һ�����Թ��������γɵĵ�����ߣ�����߶��ڵ����е�㶼���ж������ʡ�Ȼ��������չ�߶Σ�����ÿ���߶�һ�����Ե�λ������߶��ڵ������ߺ͵�㶼���˶��Զ������ʡ� �����Щ�߶ξ��й��ɻ����ԣ�����߶�������γ�һ���档��������߶��鰴���ɻ����н������У�����߶������γ�һ�����С�ͨ�������趨�����ǾͿ��Թ��ճ�����������ĸ�ij��Ρ� ������ǰ���ĸ���ֵ���ĸ����������ĸ�Ļ�����ô��������ɳ���Ϊ������ĸ��������ĸȡ��������һ�����������һ�룬��������ĸȡ��������һ����������+һ���������γ�һ�롣 2���Ժ���������ĸҪ�ص�ȷ�� �Ժ���������ĸ�������趨����ĸ����ɻ���������ݣ�ֻ����ȡ��Ҫ������ĸҪ���ǺϺ�����ܳ����� �ں����У����ɺ������Ե�Ҫ����Ҫ�У����Ρ��ʻ�����˳�����ס����������ԡ���ĸ����ĸ�������ȣ�����ЩҪ���У���������������߶��е������زģ���������������֣����������������������ԡ� �������У����ǿ��趨ÿ���߶ξ�Ϊ�����λ�㡣�������ǾͿ�ͨ���߶�������5���趨��������ĸ�����ķ�Χ�������棬��ĸ����10��40���ڽϺ����������Ϊ20��30�������ġ������������� �ں����У�������Dz��ø��ʵķ�ʽ��������һ�����߶ζ����ã���һ����������λ�ã�����γ�������������ÿ��������������㣬�����������ʾ����Ϊ�������25������λ����ʵ��ʹ���У����ܻ��е��ʱ��γ��֣���ȱ��һ������Ҫ�أ���ʱ�����ǿ���Ϊ���趨һ�������������������30������λ�� ��������Ϊ����ԭ�����ǿɽ��������ڸ��ʺ��ݱ����̼����ֲ��ķ�ʽ�����ǿɽ��������ֳ����ţ�ÿ�����������������ң����ϵ���˳�����У��������λ��ָ�����м������������С��ھ�����������������ϣ����ǿɰ���˳����һ�ʶ�Ϊ�����ڶ��ʶ�Ϊλ�������ʱ��Σ�������������Ϊλ����ʱ������������������������������˳������Ϊ������������Ʋ�����������������������������ı���λ��˳������Ϊ��λ����λ��Ʋλ����λ����λ�� �ڼ���������У���������ø��ʵķ�ʽ�����������뷽ʽ������������Թ��ڵ�����������϶�������֣���ʱ�������ڲ����Ӽ�������ǰ���£�����һ�㲻ͬ���Եĵ����λ�������뷽ʽ�ʶ����ԣ�ʹ��λ���ݷḻ��������ͨ�����뷽ʽ�ĸı��ȡ��˳��IJ�ͬ���ţ�ʹ�������ɢ�Ը��á� Ҫ���ӵ����λ������Ҫ��ԭ�м�λ�Ļ������ٽ����������������ں��������У����ֵ����Կɷ�Ϊ���½ṹ�����ҽṹ����Χ�ṹ������ṹ�������ں����������ִ��ڷ�λ�������ϡ����¡��������ң��������ڻ��ཻ����Χ������Χ��ռ�ǣ��������ǽ��������ڷ�λ��Ϊ����ʹ�ã������Ϊ�����������������������������������������������������������ͬ����ЩҪ���䲻ֱ����ʾ���ԣ�ȴ������Ϊ���Ե�λʹ�ã������ڶ�����ж��Ե�ͬʱ���ټ������е�һ�ʱ�����Ϊ������λʹ�ã����ܽ��ж��Զ��������� �ڵ����λ����İ����У����ǿ��Ƚ�������������ԣ�ʹ�䴦��ͬһ�����У������뽻���������ʣ�µ��ϡ��¡������ĸ��������ǿɰ����ִ�ͳ��д�ķ�ʽ��������д���¡�����д���ҵķ�ʽ�����ţ�������������������������ߣ���������Ҫ�����ϣ������������������Ͻǣ���������Ȼ�������½ǣ����������������������ұߣ���������Ҫ�����£������������������½ǣ���������Ȼ�������Ͻǡ��������ڵ����λ�У�ÿ�����������λ���ܰ��Լ�������������λ���ȸ��Զ�����������ݣ�����������Ӳ���� 3��ȡ��Ҫ�ص�ȷ�����ֵİ��� �ں������ֹ����У��������ֻ��Dz������Ե�һ�ʻ���ĩ�ʱ��εı��ϲ����ѣ��������ȡ�������ʱ��εĻ�����ͷ������β���ѡ�������ǰ�ͷ����ʼ���ֱ�����Ϊ����Ҫ��ʹ�ã���Ӧ�����������ף�����β��ĩ�ʱ�����ò�������λ�ù�ϵ��Ϊ����Ҫ��ʹ�ã���������Ҳ�������ѡ� ��ʱ����һ�����ֵ�ȡ���У����DZ���Խ���������λ�ˡ���������λ�Լ����������˵��Ȼ̫�٣������ɺ���������һǧ���Ʊػ���������������֡�������ǽ����ַ��������֣�������ͷ��Ҫ�غ�����β��Ҫ�������λ��ʹ��λ���ӵ���λ�Ļ�����������ɺ���������������ʮ�����ϣ����������ֱ����һ��������ı������ɿռ��½���������ͬʱ�����ǿɽ�ÿ��ȡ������λ�ķ������ڶԴ����ֵ�ȡ�롣 Ҫ�����ֲ��Ϊ�����֣���Ҫȷ��һ�ֺ��ʵIJ�ַ���������֪�����ں��ָ�����ַ��У������ַ���ʹ��������ࡢҲ�Ǽ�����ߵ�һ�ַ�������Ȼ����̸��ӡ���ʱ�������ֶ࣬����һ��Ϊ���IJ�ַ���ȴ�������ǵ��������������ϰ�ߣ����ױ����ܡ����ǿ�ѡ��ȡ���ķ����Ժ��ֽ��в�֣�ʹ���ײ��ֺͷDz��ײ��ָ���Ϊһ��ȡ����ϢԴ��ʹ������Ҫ�س��չ¶������ 4����λ˳���ȷ�� ������Ҫ��ȷ����Ҫ����λ����һ��ǡ��������˳��һ�����ʵ�����˳����ʹ�������������γɸ�����Զ����İ��ʽ��ɢ����ʹ����֮���������ĸ��ʽ��ͣ�����ʹ������������ڵı����нϺõ���ɢ�ԡ� ���ڴ������������ɣ��ɽ���ȡ��˳�����ζ�Ϊ(��һ��)ͷ + (��һ��)β + (�ڶ���)ͷ + (�ڶ���)β�� �ڵ����У��ɽ�ȡ��˳�����ζ�Ϊ(��д)ͷ + (����)β + (�Dz���)β + (��д)ͷ�� ����������ʵ��ĸ���λ�����У�����������������ǰ���ͬ���Ե����䷽ʽ���еģ��ڶ��룬���ڴ������ֵ�β������ּ������Ҳ����²��������ֲ���β��������ּ����������ϲ����ʶԵڶ���������ǰ���λ��ʽ���еġ�������������������λ���λ���������뷽ʽ��ͬ��������������ʽ����ͣ����������ǾͿ��������л���ǰ���£�ֱ�ӶԵ��ֺʹ������ȡ�롣 5����Ӧ���İ��� �ڱ����У����������Ϸ�ʽȡ�룬�����Ի��Եõ���������ʹ���ֱ����������ЧӦ�����ܶ����һ������ϸ�֣�������Ҫ���ͷŵ���������ȥ��ʹ���������ЧӦ������һ������������ʡ� ���ǿ�Ϊÿ�����趨һ����Ӧ�������ñ����ཻ״̬������ȡ���������䵽��Ӧ����ȥ�����ȡ�ø��õı���Ч���� ���ڶԵ����������λ�IJ�ͬ��������λ��ȡ��Ӧ�����й����״̬�������ģ�����ӦҪ���������ɵ����״̬�³��ֵģ�����ȡ��Ӧʱ��������Ϊ�Զ�Ӧ�����ռ��ʹԭ�ȵ���ɢ���ü��٣�������������Եķḻ�ͱ�����ʽ�Ķ����ԣ�ʹ�����������������ܼ��٣��Ե��ֻ���ﱾ��Ҳ����ܺõ���ɢ���á���Ӧ���У�����Ҫ��֮��Ķ��Զ�����ϵ��ֱ�ۣ��ʲ���ʱ���ѶȲ�����Ϊ��Ӧ��������������Ӻܶࡣ 6����λ��������� �����ּ�λȷ��֮��ҪΪ������һ����Ӧ�Ĵ��롣���ڼ�λ�ǰ����б��Ƶģ��������ɷ����Ĵ����λ�Ĵ��룻�������Dz��õ����λ���������Ĵ����ֿɷ�Ϊ�����������λ�������롣 λ��Ҫ�������֣�����λ����λ��Ʋλ����λ����λ���ɷֱ��ô��롪��|��/��\���^��ʾ�� ��������Ҫ�������֣���������������Ʋ�����������������������ɷֱ��ô��롪��|��/��\���^��l ��ʾ�� λ������Ҫ�������֣����������������������������������������ɷֱ���ͼ�η��ű�ʾ��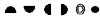 λ����ͼ�η��ŵĺ������ڣ��������ʾ�����ڷ�λ����Ϊ�Ҷ�Ӧ���ṩ���㣨�����DZ�������Ӧ����λ������Ӧ��ֻҪ�ҳ��γ�һ������Բ����һ���֣������ҵ��˶�Ӧ������ 7����λӦ�õķ�ʽ ���ڼ������������ʱ��ÿһ������λ�����Ҫ�ؿɸ������ڼ����е�λ����һ����Ӧ�ļ���ȥ���棨�����ּ�λ���λͼ����������С���̺�������ʱ�����ð��������ּ�����һ��ķ�ʽ���в�������С���̼�λͼ���������ں��ּ���������ʱ�����ô����ң����ϵ��µķ�ʽ����������ֱ���һ�����������ġ��塢����ʾ���������λ�ֱ���1��2��3��4��5��ʾ�������ּ�λ��������ͼ���� 8����ϸ�ֹ���İ��� ��������Ҫ��ĵط��������û�����ȡʣ���δ�ñ��ν���ϸ�ֹ���ÿ���ֳַ��Ⱥ���Ϊ����������д˳�����ȡ����ԣ���ȡ���������ķ�ʽȡ���ʣ�����ȡ�������ε���ȡ���ʣ����ײ�����Dz��ײ��ֱ��β���ͬʱȡ���ķ�ʽ��������ȡ�룬ֱ�����ֵı���ȫ�����꣬���������룬���ٽ���ƴ����ĸ����������ϸ�֡� ����ÿ����һ����λ�������������������һ�����μ�����������������ϸ�ֺ�������ĸ��ʽӽ����㡣���ڻ�����ȡ���δ�ñ���ʹ�������ϸ���һЩ���ɹ涨ϸ�ֹ���ȡ��ʱ��ȡ��Ӧλ�����ڻ�������á������߽��������ʾ���𡣶�ȡ�����������������֣����п����������У����������������ʱ���ɰ��������������У����������ϣ������ϸ�ֹ���ȷ����˳���������У���ϸ��ʱ�ı���һ�㲻�ñ������ҪʱҲ�ɱ������ʾ�ã����Ա�֤���д����һ���ԡ� 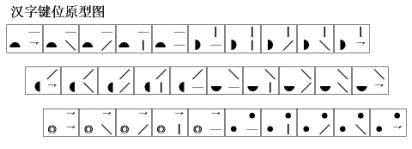
�� | 


